my spidey sense is tingling..
4
behold the quaternity
my god...


PeakOil is You
Results Published 31 Dec 2008: 1 through 99.
Re: Please type any one number between 1 through 99.
![]() by ArchetypalArchie » Tue 30 Dec 2008, 10:50:14
by ArchetypalArchie » Tue 30 Dec 2008, 10:50:14
-

ArchetypalArchie - Wood

- Posts: 1
- Joined: Tue 30 Dec 2008, 04:00:00
Re: RESULTS PUBLISHED 31DEC2008: 1 through 99.
![]() by angrybill » Tue 30 Dec 2008, 18:04:20
by angrybill » Tue 30 Dec 2008, 18:04:20
$this->bbcode_second_pass_quote('angrybill', 'I') will publish the results when completed.
This would be easier if an administrator could allow for buttons of 1-99, otherwise you will need to type in your number.
------------------------------------------------------------------------------------
The original question was asked: Pick a number from 1 through 99 but in reality I could have said just pick a number because the only number in this study is the first-digit law or Bedford's Law. leading # Number of occurances % Benfords Law
1 10 24.39% 1 30.10%
2 4 9.76% 2 17.60%
3 5 12.20% 3 12.50%
4 5 12.20% 4 9.70%
5 2 4.88% 5 7.90%
6 5 12.20% 6 6.70%
7 5 12.20% 7 5.80%
8 2 4.88% 8 5.10%
9 3 7.32% 9 4.60%
Total # 41 100.00% 100.00%
Conclusion:
This would be easier if an administrator could allow for buttons of 1-99, otherwise you will need to type in your number.
------------------------------------------------------------------------------------
The original question was asked: Pick a number from 1 through 99 but in reality I could have said just pick a number because the only number in this study is the first-digit law or Bedford's Law. leading # Number of occurances % Benfords Law
1 10 24.39% 1 30.10%
2 4 9.76% 2 17.60%
3 5 12.20% 3 12.50%
4 5 12.20% 4 9.70%
5 2 4.88% 5 7.90%
6 5 12.20% 6 6.70%
7 5 12.20% 7 5.80%
8 2 4.88% 8 5.10%
9 3 7.32% 9 4.60%
Total # 41 100.00% 100.00%
Conclusion:
Everyone's number was included.
http://en.wikipedia.org/wiki/Benford's_law
-

angrybill - Peat
- Posts: 78
- Joined: Thu 27 Nov 2008, 04:00:00
Re: RESULTS PUBLISHED 31DEC2008: 1 through 99.
![]() by angrybill » Tue 30 Dec 2008, 18:29:43
by angrybill » Tue 30 Dec 2008, 18:29:43
# topics/posts leading # % Benfords Law
1 20 33.33% 1 30.10%
2 14 23.33% 2 17.60%
3 8 13.33% 3 12.50%
4 4 6.67% 4 9.70%
5 5 8.33% 5 7.90%
6 2 3.33% 6 6.70%
7 5 8.33% 7 5.80%
8 0 0.00% 8 5.10%
9 2 3.33% 9 4.60%
Total # 60 100.00% 100.00%
What I did here is take all the leading digits from the main forum page and since these are random numbers they do indeed conform to Benford's Law, at least more so than what our choices of numbers were (probably because some we chose birthdays and ages). I think this is interesting and hope you'll have the time to read and test it yourself in some way. A great new year for all.
1 20 33.33% 1 30.10%
2 14 23.33% 2 17.60%
3 8 13.33% 3 12.50%
4 4 6.67% 4 9.70%
5 5 8.33% 5 7.90%
6 2 3.33% 6 6.70%
7 5 8.33% 7 5.80%
8 0 0.00% 8 5.10%
9 2 3.33% 9 4.60%
Total # 60 100.00% 100.00%
What I did here is take all the leading digits from the main forum page and since these are random numbers they do indeed conform to Benford's Law, at least more so than what our choices of numbers were (probably because some we chose birthdays and ages). I think this is interesting and hope you'll have the time to read and test it yourself in some way. A great new year for all.
-
angrybill - Peat
- Posts: 78
- Joined: Thu 27 Nov 2008, 04:00:00
Re: RESULTS PUBLISHED 31DEC2008: 1 through 99.
![]() by jasonraymondson » Tue 30 Dec 2008, 19:01:11
by jasonraymondson » Tue 30 Dec 2008, 19:01:11
no more weed for you
- jasonraymondson
- Permanently Banned
- Posts: 2727
- Joined: Wed 04 Jul 2007, 03:00:00
- Location: Peace Out
Re: RESULTS PUBLISHED 31DEC2008: 1 through 99.
![]() by yippleflipple » Tue 30 Dec 2008, 19:15:45
by yippleflipple » Tue 30 Dec 2008, 19:15:45
it's 5! how could i have been so blind
-
yippleflipple - Peat
- Posts: 71
- Joined: Sat 13 Sep 2008, 03:00:00
Re: Results Published 31 Dec 2008: 1 through 99.
![]() by Daniel_Plainview » Tue 30 Dec 2008, 19:48:24
by Daniel_Plainview » Tue 30 Dec 2008, 19:48:24
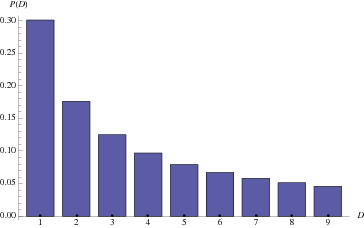
Benford distribution:
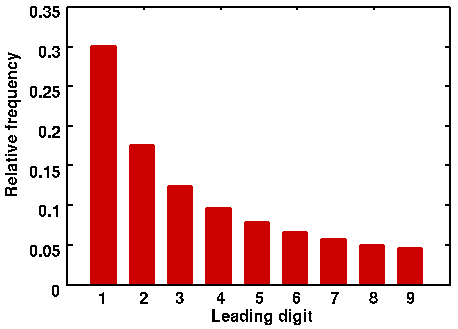
Randomly selected street addresses:
Randomly selected street addresses:
-

Daniel_Plainview - Prognosticator

- Posts: 4220
- Joined: Tue 06 May 2008, 03:00:00
- Location: 7035 Hollis ... Near the Observatory ... Just down the way, tucked back in the small woods
Re: Results Published 31 Dec 2008: 1 through 99.
![]() by angrybill » Tue 30 Dec 2008, 23:30:27
by angrybill » Tue 30 Dec 2008, 23:30:27
$this->bbcode_second_pass_quote('DoomWarrior', '[')b]Benford distribution:
Randomly selected street addresses:
Those histograms are correct for the Benford Law distribution. Warrior, do you know how I could upload my pie chart for the data collected. It wasn't so easy to clearly put the results in this forum but I'm glad you looked it up.Randomly selected street addresses:
-
angrybill - Peat
- Posts: 78
- Joined: Thu 27 Nov 2008, 04:00:00
Re: Results Published 31 Dec 2008: 1 through 99.
![]() by yippleflipple » Wed 31 Dec 2008, 00:44:40
by yippleflipple » Wed 31 Dec 2008, 00:44:40
this is really interesting.. is there something specific or fundamental that causes this shape in nature?? Im no math whiz but seems like it can be applied to human behavior, or maybe thats just me 
-
yippleflipple - Peat
- Posts: 71
- Joined: Sat 13 Sep 2008, 03:00:00
Re: Results Published 31 Dec 2008: 1 through 99.
![]() by Tanada » Wed 31 Dec 2008, 01:47:56
by Tanada » Wed 31 Dec 2008, 01:47:56
$this->bbcode_second_pass_quote('yippleflipple', 't')his is really interesting.. is there something specific or fundamental that causes this shape in nature?? Im no math whiz but seems like it can be applied to human behavior, or maybe thats just me
For any series of values in increasing order you always start low and get larger. Seems simple enough right? Well as a consequence of that fact if you have less numbers than the entire set any random sampling will be weighted towards the low end.
Take the street address numbers as an example. Almost any street is going to have a 100 block, and except for really short streets a 200, 300 and 400 as well. However there are many streets in a randomly constructed city that are not more than 19 blocks in leangth on one side of the dividing line (e-w or n-s in most cities) So if a city grid is 8 blocks to the mile and the average small city is 3 miles across then you will get blocks 100-1200 in each direction assuming equal distribution. This gives you blocks 100, 1000, 1100 and 1200 all starting with a 1. Now add a little complexity, say the city is 3 miles by 4 miles roughly rectangular in shape. That gives you another array of block numbers from 100-1600 in the other direction, which leaves you with a second data set of 100, 1000, 1100, 1200, 1300, 1400, 1500, 1600 all trending to give you a 1 as the first didget. By the same token you have only 200, 300, 400, 500, 600, 700, 800, 900 to give you 2, 3, 4, 5, 6, 7, 8, 9. Unless the city is carefully planned and rigorously laid out you will have subdivisions and side streets and such cropping up that will add more low numbers like 200 and 300 but less high numbers like 800 and 900. Throw all those random values in and you get more of any value as it aproaches 1 and your graph makes one of those neat declining value curves as shown above.
Now go back and look at Angrybill's data. Because the set of possible numbers was 1-99 and only 41 inputs were used not every number was picked. Presuming that there were no doubles a truely random sample would give nearly equal values for first didget 1-9, however people like certain numbers and are predisposed to choose them. For example I picked 23 because its my favorite number and has been since around 1980, it has nothing to do with that Jim Carey movie of a couple years ago. Based on Angrybill's data only 4 numbers in the 2 set were picked out of 41. In a truely random sample that would be dead on, each of the subsets has 11 possible intergers for example 9, 90-99 or 3, 30-39. 41 choices gives you 4.55 per subset. However 1, 10-19 received 10 entries instead of 4.55 while 5, 50-59 and 8, 80-89 each only received 2. Assuming no doubles then 10 of the 11 possible for 1, 10-19 were chosen. To really get a Bedford's Law type distribution you have to sample a statistical universe of subsets, Angrybill only has one sample set of 41 answers to work with. In the street adress number sample the numbers came from a lot of different streets, i.e. from an array of subsets, not a single subset.
As someone mentioned a lot of people asked this question will pick a partial birthdate, and here again the artificial rules that govern a calender weight things to the low end. If you pick day of the month you max out at 31 choices, 1-31. That gives you 11 in the 1, 10-19, 11 in the 2, 20-29 but only 3 in the 3, 30, 31. Now add in that 5 months have 30 days and one month has 28/29 and you put even more emphasis lower on the set. What about those who pick their birth month instead? Well that gets you 1, 10, 11, 12 for the 1 interger and only one occurence of the remaining numbers.
Is that clear as mud for you now?
$this->bbcode_second_pass_quote('Alfred Tennyson', 'W')e are not now that strength which in old days
Moved earth and heaven, that which we are, we are;
One equal temper of heroic hearts,
Made weak by time and fate, but strong in will
To strive, to seek, to find, and not to yield.
Moved earth and heaven, that which we are, we are;
One equal temper of heroic hearts,
Made weak by time and fate, but strong in will
To strive, to seek, to find, and not to yield.
- Tanada
- Site Admin

- Posts: 17094
- Joined: Thu 28 Apr 2005, 03:00:00
- Location: South West shore Lake Erie, OH, USA

